We humans are very interguied with the future, Our future. What’s instored for us has been a money mining business of the fortune telling. But what if I say that we finally have a more reasonable solution to get these answers?
Data science proves that with logical calculated and authentic results. Here are a few reasons I think data science could or has the answers!
Picture credit -aiasia
Can Data science help predict future calamities?
Yes, data science can help predict future calamities. There are a number of ways that you can use data science to predict which events will happen in the future.
First, you can model the probability of an event happening given a set of inputs and outputs. For example, you can predict the probability of an earthquake occurring given a set of input parameters.
Second, you can build a predictive model that tries to predict the probability of an event happening and starts with no prior information. For example, you might build a predictive model that predicts the probability of an earthquake occurring given current input parameters.
Third, you can use machine learning to develop predictive models on historical data. For example, a machine learning algorithm could be trained on historical data to predict the probability of an earthquake occurring at a specific location given current parameters.
Picture credit – research for disaster management Maryland
The near future and recent researching
Hi!
I am Dr. Robert White, a professor of risk and insurance at the University of Maryland. I have studied data science for the last 10 years and I helped create an algorithm that could predict future calamities.
We can use data science to help predict future calamities, but it’s not easy. I’ve spent the past 10 years trying to find a way to predict earthquakes that would be reliable and accurate.
Can data science help predict future calamities? Absolutely!
Machine Learning is becoming a mainstream technology with a lot of potential applications. The automotive industry is one of the fastest growing markets for machine learning. Many of the analytic systems, such as image analysis, speech recognition, and natural language processing, are now being implemented in the automotive industry. Machine learning is a powerful tool that can be used to make predictions and forecasts for the automotive industry. In the report, we cover predictions for the market size and forecasts for the automotive industry.
1. Introduction
Machine learning predictions for the automobile market size and forecast for 2028. Machine learning predictions for the automobile market size and forecast for 2028. Machine learning predictions for the automobile market size and forecast for 2028. Machine learning predictions for the automobile market size and forecast for 2028. Machine learning predictions for the automobile market size and forecast for 2028. Machine learning predictions for the automobile market size and forecast for 2028. Machine learning predictions for the automobile market size and forecast for 2028. Machine learning predictions for the automobile market size and forecast for 2028. Machine learning predictions for the automobile market size and forecast for 2028. Machine learning predictions for the automobile market size and forecast for 2028.
2. Machine Learning Predictions for the Automotive Market Size
Machine Learning Predictions for the Automobile Market Size: Machine Learning Predictions for the Automotive Market Size: Machine Learning Predictions for the Automotive Market Size: Machine Learning Predictions for the Automotive Market Size: Machine Learning Predictions for the Automotive Market Size: Machine Learning Predictions for the Automotive Market Size: Machine Learning Predictions for the Automotive Market Size: Machine Learning Predictions for the Automotive Market Size: Machine Learning Predictions for the Automotive Market Size: Machine Learning Predictions for the Automotive Market Size: Machine Learning Predictions for the Automotive Market Size: Machine Learning Predictions for the Automotive Market Size: Machine Learning Predictions for the Automotive Market Size: Machine Learning Predictions for the Automotive Market Size: Machine Learning Predictions for the Automotive Market Size: Machine Learning Predictions for the Automotive Market Size: Machine Learning Predictions for the Automotive Market Size: Machine Learning Predictions for the Automotive Market Size: Machine Learning Predictions for the Automotive Market Size: Machine
3. Machine Learning Predictions for the Automotive Market Forecast
Machine Learning Predictions for the Automobile Market Size and Forecast for 2028 Machine learning is a type of artificial intelligence that is capable of learning from data and making predictions. Machine learning is being used in the automotive industry in order to make predictions about the future of the market. Using machine learning, the automotive industry has been able to make predictions about the future of the automotive industry. Machine learning is predicted to make more than $2 billion in revenue by 2028. Machine learning is predicted to make a significant increase in revenue because of the rise of autonomous and electric vehicles.
4. Conclusion.
Machine learning predictions can be made by analyzing historical data sets and then applying the same techniques to new data sets. This allows the machine learning predictions to be made with accuracy. The machine learning predictions can be made by analyzing historical data sets and then applying the same techniques to new data sets. This allows the machine learning predictions to be made with accuracy. Machine learning predictions for the automobile market size and forecast for 2028. Machine learning predictions for the automobile market size and forecast for 2028. Machine learning predictions for the automobile market size and forecast for 2028. Machine learning predictions for the automobile market size and forecast for 2028. Machine learning predictions for the automobile market size and forecast for 2028. Machine learning predictions for the automobile market size and forecast for 2028.
Data collection is becoming an increasingly important part of the world we live in. Companies, schools, and others are collecting data from all around us. This data can come from a variety of sources from a customer survey to a data-driven marketing campaign to an email that you just want to send.
If you’re collecting personal information, then you need to make sure that you are doing everything in your power to protect the safety of the personal information you collect. This blog post will tell you all you need to know about taking the right precautions in order to collect data in a safe and secure way.
1. The importance of data collection
Collecting data is important because it helps the company make better decisions. Data collection is a vital part of the business world. Without data, companies cannot make decisions about the products they are selling, the services they are providing, or the marketing campaigns they are conducting. Data collection can be as simple as collecting customer feedback or as complex as collecting information about the world’s climate. Regardless of the type of data you collect, it is important to keep in mind the steps to take when collecting and storing data.
2. The steps to take when collecting data
There are many steps to take when collecting data. You should always take the time to do a risk assessment, which will help you decide if you should collect the data or not. You should also make sure that you are collecting the data for the right purpose. You should also make sure that you are collecting the data in a way that is as safe as possible. There are many things that you can do to make sure that the data is collected safely. For example, you can ask the person being interviewed how they would feel if they were being watched while they are being interviewed. You can also ask if they would be okay with you recording the interview in a video or audio file. These are just a few of the many things that can be done to make sure that the data is collected safely.
3. Conclusion.
It is important to take precautions when collecting data. It is important to know the steps to take when collecting data. It is also important to know the associated risks of collecting data. In order to ensure that you do not have any accidents, you should always practice the following steps: – Be sure to have a data collection plan. – Be sure to have an emergency plan. – Be sure to have a backup plan. – Be sure to have a contact list. – Be sure to have a list of what you are collecting data for. – Be sure to have a list of what you are collecting data from. – Be sure to have a list of what you are not collecting data from. – Be sure to have a list of what you are not collecting data for. – Be sure to have a list of what you are not collecting data from. – Be sure to have a list of what you are not collecting data for. – Be sure to have a list of what you are not collecting data from. – Be sure to have a list of what you are not collecting data for. – Be sure to have a list of what you are not collecting data from.
4.Data collection is an essential part of many businesses.
Without it, many companies would not be able to function. However, there are some regulations that have to be followed when collecting data. There are some safety steps that have to be taken in order to ensure the safety of the data you are collecting. These include: – Doing the research to ensure the data you are collecting is not dangerous. – Making sure the data you are collecting is not illegal. – Notifying the data subject that you are collecting data. – Making sure the data you are collecting is not personal information. – Making sure the data you are collecting is legal. – Making sure that the data you are collecting is not being collected in a way that violates the law. – Making sure the data is being collected in a way that is ethical. – Making sure that the data is being collected in a way that is not violating the law. – Making sure the data is not being collected in a way that is not ethical. – Making sure the data is not being collected in a way that is
This is a game-changer for all developers, editors, and designers since you now have an option to do your work for free
Adobe is probably one of the biggest suits of applications for computer professionals. It has enough apps to almost cover up everything in computer workflow, from pdf readers to creation tools, to editing and even VFX tools which are so unique and bleeding edge, that no software could replace Adobe’s software(like after effects, dreamviewer, etc).
What Just Happened?
Adobe officially announced, that it would have many of its applications, like photoshop, etc into a web version, wherein you could just get it easily from a web URL. It does not matter what Operating System or system specifications you are using(although it does matter what system specifications you are using
This Leads To…
Now it’s not just that adobe is gonna be completely available on all computers with web browsers. It’s also free to use. Ok… When I say “Free To Use”, I meant free as in free of cost, and not free as in
freedom(It still has extremely strict licenses as usual).
The apps could be used just like that, without spending any money, although I’m almost certain that it’s gonna be a more freemium model rather than “completely free of cost”
However
As you might guess, Adobe did not make all it’s software free. I mean… It made only the web version of some software which is free the native desktop applications are still completely paid(other than that 30 day trial).
I’m gonna be clear… Not all softwares of Adobe suit are gonna be free. And the ones which are gonna be free will have a pay wall of “premium features”
The Result?
I’m certain that this would negatively affect software like Inkscape, GIMP, PDF Readers, DaVinci resolves, and other apps which were… Well… making use of the fact that Adobe software is not free. But now that things are gonna change, I’m sure the graph would go down, although this would be a short and temporary change.
BUT, this also will increase the number of people using software like Linux, since Adobe was bound to Windows, and Mac… and now it isn’t.
It was VSCode, through GitHub codespace, then apps like photopea and other graphic editing apps to “replace” photoshop for free, but now, many of these apps are available in the app version. With that said, predicting the future from the present, I’m sure that we will have fewer apps made for the computer and more apps for the web, considering that it has too many advantages, from availability to ease of opening and using, to solving problems like storage issues and so on.
Wrapping Up…
This is a huge change in the software world and I hope Adobe makes more changes like this. I’ll post more videos and updates of all the software and fun stuff on YouTube.
Well, that’s really it in this article, I hope you guys got something from this, and… I’ll meet you in the next one.
I am pleased to announce the rollout of CUPED for all our customers. Statsig will now automatically use CUPED to reduce variance and bias on experiments’ key metrics. This gives you access to a powerful experiment tool being used at top tech companies like Microsoft, Facebook, Airbnb and more.
CUPED is a technique where we leverage pre-experimental data to reduce variance and pre-exposure bias in experiment results. This can significantly shrink confidence intervals and p-values, reduce the required sample sizes (and correspondingly durations) needed to run experiments, and will ultimately help you to move more quickly and with more confidence.
How this will help you
Waiting for experiments to gather sufficient sample size can be a major blocker to companies at any scale. Because of this, various techniques have been developed to reduce the variance (or “noise”) in experimental data, and reduce the amount of time teams spend waiting for results.
CUPED (Controlled-experiment Using Pre-Experiment Data) is one of these techniques, publicized for this use case by Microsoft in 2013. In our implementation, we use users’ metrics from the period just before an experiment launched to adjust their metrics for that experiment. This can help to reduce variance and bias, which we’ll jump into below.
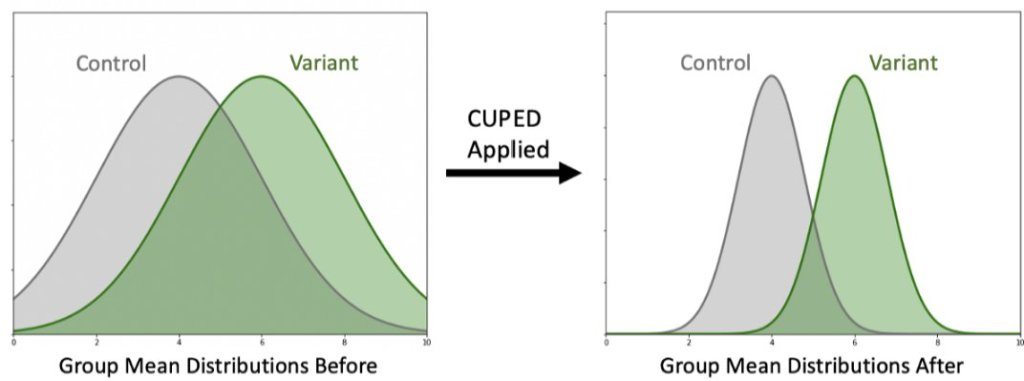
Variance Reduction
In the hypothetical example below, we run an experiment that increases our mean metric value from 4 (control) to 6 (variant). However, because of the noise in the population there’s a lot of uncertainty in this estimate, and it’s unclear if the data is showing a real difference.
Applying CUPED improves the precision of our mean estimates, and makes it clearer that the populations are different. For the experimenter, this means smaller confidence intervals and lower p-values at the same effect size.
This works by using pre-experiment data to “explain” some of the observed variance. Instead of treating users’ metric outcomes as only depending on their experiment group, we treat each user’s metrics as being based on both their experiment group and their own past behavior. The more users’ past behavior is correlated with their future behavior, the more variance we can explain away in this way
Bias Correction
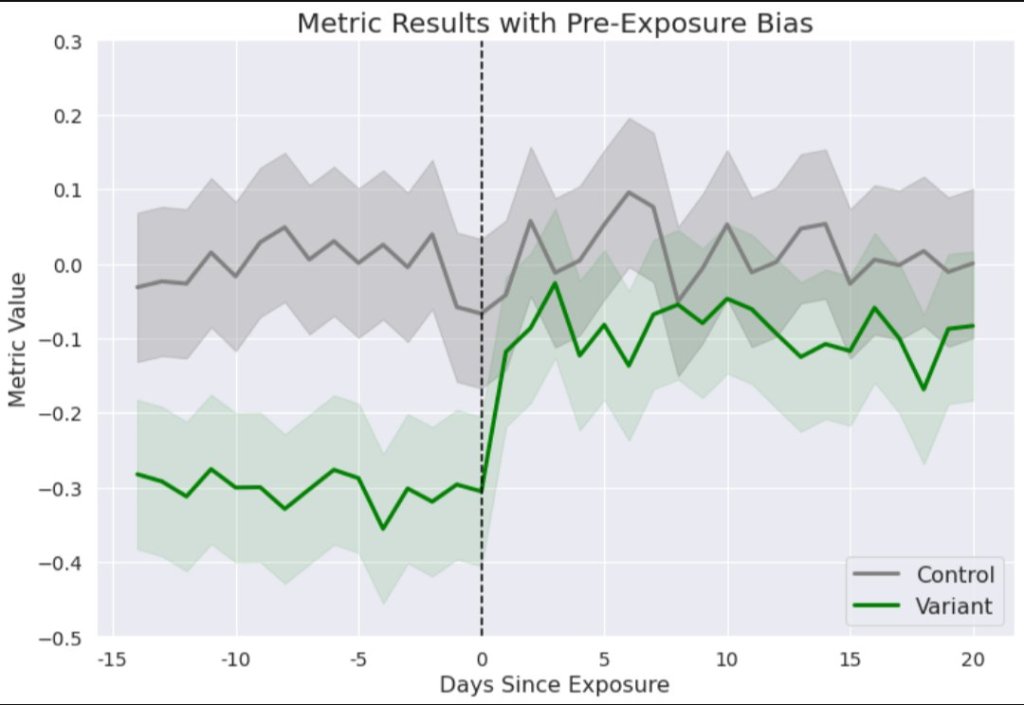
Randomisation doesn’t result in perfectly balanced groups. In rare cases you will see large differences between groups even before an experiment started, which is referred to as pre-exposure bias. In addition to variance reduction, CUPED is also a way to reduce pre-exposure bias.
In the chart below, we see an experiment whose results would look fairly neutral. However, it’s clear that users saw a meaningful lift after they were exposed to the variant — they just started off with much lower values. (It’s worth mentioning that a bias this extreme is very rare!)
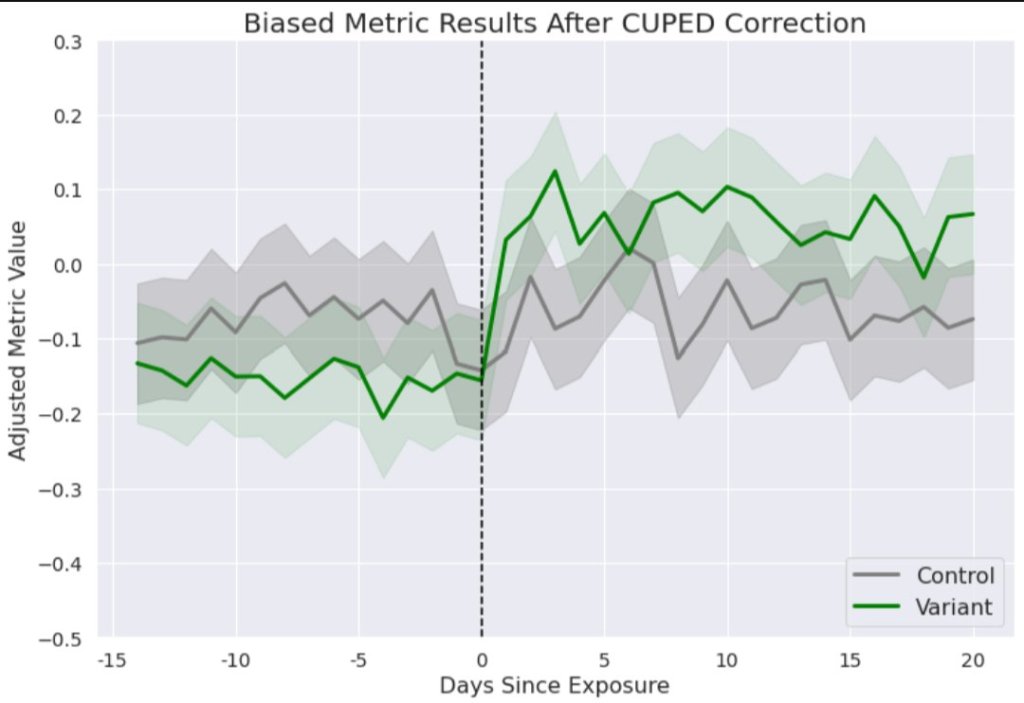
CUPED can shrink this gap. Users who had higher-than-average pre-exposure data will have their metrics adjusted downwards, and vice versa. Accordingly, if the average user in the Variant group had a lower pre-experiment metric than the average user in Control, CUPED will close this gap by reducing the average Control user’s metric and increasing the average Variant user’s metric.
If we apply the adjustment to both the pre and post-exposure values to demonstrate, the CUPED-adjusted values might look like the chart below, closing some of the gap between the pre-exposure metrics.
Now the results will reflect the reality that this experiment drove an increase for users in the test group!
Our Approach
Following Statsig’s values, we’re shipping this quickly so that you can ship quickly. We’re using a simple and battle-tested version of this approach, where we use a user’s metric value from before an experiment starts to reduce the variance on that same metric in your experiment results.
We’ll be monitoring this as it rolls out to understand how effective this is and if there’s any next steps we can take to level up our approach.
Early Results
We don’t want you to have to wait for a full-fledged white paper before we give you a peek under the hood, but we also don’t want to only give you vanity stats on this tool. Here’s a brief rundown of the results we’ve seen in testing.
Sample Size / Variance Reduction
To understand the impact this will have on sample sizes, we looked at relevant experiment metrics (see note below) from 300+ customers to see how much CUPED would reduce required sample sizes (and experiment run times) due to lower metric variance:
Based on those results, we’re confident that CUPED will help people to move faster, with more confidence. It isn’t a magic bullet which makes every experiment run twice as fast, but we can already see that the value is there on real customer experiments.
This drop in required sample size corresponds to more precise results for the same sample size. An experiment where CUPED would reduce the required sample size by ~50% would shrink confidence intervals by ~30% if you kept the original sample size — leading to more Statistically significant results.
Significance
On the same set of experiments, we saw that about 9% of experiments had a key metric turn out to be statistically significant* after applying CUPED, where it was previously not statistically significant. This is because of some combination of variance reduction and reducing a pre-exposure bias that previously made the experiment look less impactful than it was.
Conversely, about 2% of experiments saw a previously statistically significant result turn out to not be statistically significant. This is an important result! The likely explanation is that experiments which were previously false positives due to pre-exposure bias are now correctly categorized — meaning those results are more accurate.
How to work with CUPED
The effectiveness of CUPED varies across user populations and metrics. It’s worth knowing what to look for!
The more stable a metric tends to be for the same user over time, the more CUPED can reduce variance and pre-experiment bias
CUPED utilizes pre-exposure data for users, so experiments on new users or newly logged metrics won’t be able to leverage this technique
Getting in the habit of setting up key metrics and starting to track metrics before an experiment starts will help you to get the most out of CUPED on Statsig
It’s common for growth-stage companies to be running lots of experiments focused on new user acquisition and conversion. We also have lots of companies which are new on the platform and tend not to have all of their logging set up. As companies mature in their usage and adoption of Statsig, we expect to see CUPED become more and more effective.
For the analysis above, we limited our dataset to experiments where over 50% of the users in the experiments could have CUPED adjustments applied. This filters out experiments with mostly new users, or metric results on metrics which don’t have sufficient history to calculate pre-experiment data.
Let’s Ship!
CUPED-adjusted results will be available in your key metric results across all experiments in the new results card in the coming days. Look for the “CUPED” flag above your key metrics.
Give it a try, check out the docs, and let us know how it’s working for you!
Data scientists and decision scientists do very different, though equally important, work. Here’s how to tell the difference.
B Siddharth Rao -Founder BetaDATA.india
At Instagram, we had many different job roles that analyzed data. A few of the data job titles included: data scientist, analyst, researcher and growth marketing.
There’s often a lot of confusion between the roles of data scientist vs. decision scientist.
We had both at Instagram and they fulfilled different needs, so I thought I’d explain the main differences I see from my personal experience in the decision science role, working closely with my data science colleagues.
Data Science versus Decision Science
The data scientist focuses on finding insights and relationships via statistics. The decision scientist is looking to find insights as they relate to the decision at-hand. Example decisions might include: age groups on which to focus, the most optimal way to spend a yearly budget or how to measure a non-traditional media mix. For decision scientists, the business problem comes first; analysis follows and is dependent on the question or business decision that needs to be made.
Data Scientists vs. Decision Scientists: How to Think About Data
Thinking drives action, so I’ll compare each role by reviewing the way data scientists and decision scientists differ in terms of thinking about data.
DATA SCIENTISTS
Data is the Tool for Improving and Developing New Products Based on Robust Statistical Methods
Data scientists are looking to understand, interpret and analyze with the goal of building better products. Therefore, data quality, statistical rigor and measurement perfection are often their trademarks.
For data scientists, the analysis, statistical rigor and understanding comes first. Business challenges come second.
Data scientists think about data in terms of data patterns, data processing, algorithms and statistics. Often, data scientists are conducting deep analysis and experimental statistics. They are obsessed with finding causal relationships.
Data scientists are deeply focused on data quality as it relates to their product area because better data quality results in more thorough statistical analysis.
Data scientists frame data analysis in terms of algorithms, machine learning, statistics and experimentation. They are looking to bring order to big data to find insights and learnings as they relate to their product or focus area. They have a statistics lens to everything they do.
Data scientists’ north star goal: Use high-quality data and robust statistics to support product development.
DECISION SCIENTISTS
Data is the Tool to Make Decisions
Decision scientists frame data analysis in terms of the decision-making process. They are looking at the various ways of analyzing data as it relates to a specific business question posed by their stakeholder(s).
Other names for this role may include: analytics, analyst and applied analytics.
The data scientist focuses on finding insights and relationships via statistics. The decision scientist is looking to find insights as they relate to the decision at-hand. Example decisions might include: age groups on which to focus, the most optimal way to spend a yearly budget or how to measure a non-traditional media mix. For decision scientists, the business problem comes first; analysis follows and is dependent on the question or business decision that needs to be made.
The decision scientist therefore needs to take a 360-degree view of the business challenge. They need to consider the type of analysis, visualization methods and behavioral understanding that can help a stakeholder make a specific decision.
In other words, decision scientists need to make insights usable. They need to be able to work with a variety of data sources and inputs — each selected based on its ability to help answer the business question. This means a decision scientist needs to have a strong business acumen as well as a robust analytical mind. You cannot have one without the other in a decision science role.
Sometimes, measurement won’t be perfect. Business tactics aren’t always neat and tidy. For example, there is almost no clean way to create a test and control for viral or celebrity marketing, but these are both legitimate marketing approaches and the decision scientist needs to be okay with that. Businesses shouldn’t take an action so that it can be measured, but because it is the right thing to do; measurement comes next.
Sometimes a clean, causal experiment is possible and sometimes it isn’t. Decision scientists need to have a keen sense of when it’s appropriate to move forward with a decision based on correlations and when they need to push for a clean experiment. It all comes back to the business context and the decision at-hand.
Decision scientists’ north star goal: use data and statistics to support business decision making, budgeting and marketing spend.
Why does decision science matter !
Data Science vs. Decision Science: In the Real World
In my own experience at Instagram, each data scientist was dedicated to one specific product or product feature. They spend a lot of time ensuring the data logging is accurate for that product area by running statistical analysis on trends and using complex visuals to display their type of analysis. They have a deep knowledge of their product, but not the ecosystem.
If the product changes or we launch new features attached to their product, the data scientist is responsible for both logging the new data and measuring the uptake of the new features.
On the flip side, I was in the decision science job group. My team and I supported the marketing group and the marketing leadership in helping them make decisions about marketing budgets and priorities.
I relied heavily on the tables, logging and analysis from my data science colleagues as the basis for our marketing activities. I then augmented their work with my own analysis to help our marketing leadership make decisions on where and when to spend marketing budget.
My visuals were designed for consumption and business action, and therefore had a different goal than the data scientists’ goal of using visuals to display complex analysis.
Because data scientists focus on one product area only, my analysis tended to look at relationships across products and the impact of demographics on product behavior at the company level.
My decision science team is the only team that looks at the full ecosystem on a regular basis because marketing decisions revolve around wanting to understand how one behavior interacts with another.
As you can hopefully see, there are some subtle but important differences here.
The decision scientist sits hip-to-hip with decision makers and management to help them make the best decisions for the business. Decision scientists are equal parts business leader and data analyst.
The data scientist sits hip-to-hip with data and statistical rigor. Data scientists are relentless about quality and deep analyses that drive products to scale and develop based on usage data.
Each role is necessary and critically important.
Decisions need to be made quickly to keep the business moving forward based on what is knowable now. This is the job of the decision scientist.
The business also needs to grow, scale and build better products. Deep product knowledge, a high standard of data quality and statistical rigor help ensure they’re pulling out the best insights so product leaders understand their domains. This is the job of the data scientist.
A business needs to both move forward with decision making while also improving its products for the longer term, so the decision scientist and the data scientist both contribute to the greater health of the company.
A team of academic researchers introduced an attack technique that could disrupt 5G networks, requiring new ways to protect against adversarial machine learning attacks.
B Siddharth Rao
A research paper published this week has called into question the security protections placed on 5G networks.
A team of academic researchers from the University of Liechtenstein claimed that a surprisingly simple strategy for jamming networks could allow an attacker with zero insider knowledge to disrupt traffic on next-generation networks, even with advanced defenses. The key to the attacks, according to the research team, is the use of an adversarial machine learning (ML) technique that does not rely on any prior knowledge or reconnaissance of the targeted network.
In a research paper published on July 4, the team described how the shift to 5G networks has enabled a new class of adversarial machine learning attacks. The paper, titled “Wild Networks: Exposure of 5G Network Infrastructures to Adversarial Examples,” was authored by Giovanni Apruzzese, Rodion Vladimirov, Aliya Tastemirova and Pavel Laskov.
As 5G networks are deployed, and more devices begin to use those networks to move traffic, the current methods of managing network packets no longer hold up. To compensate for this, the researchers noted, many carriers are planning to use machine learning models that can better sort and prioritize traffic.
Those machine learning models proved to be the weak point for the attack, as confusing them and redirecting their priorities will let attackers tinker with how traffic is handled. The researchers suggested that by flooding the network with garbage traffic, a technique known as a “myopic attack” can take down a 5G mobile setup.
The base idea, the researchers wrote, lies in making slight changes to the data set. By doing something as simple as a data packet request appended with additional data, a machine learning setup would be fed unexpected information. Over time, those poisoned requests could modify the behavior of the machine learning software to thwart legitimate network traffic and ultimately slow or stop the flow of data.
While the real-world results would depend on the type of 5G network and machine learning model being deployed, the research team’s academic tests produced resounding results. In five out of six lab experiments performed, the network was taken down using a technique that involved no knowledge of the carrier, its infrastructure or machine learning technology.
“It is simply required to append junk data to the network packets,” Apruzzese told Search Security. “Indeed, [one example] targets a model that is agnostic of the actual payload of network packets.”
The results are relatively benign in terms of the long-term effects, but by triggering service outages and slowing network traffic, they would certainly cause a problem for those hoping to use the targeted network.
More important, the team said, is how the research underscores the need for a better model to test and address vulnerabilities in the machine learning models that future networks plan to deploy in the wild.
“The 5G paradigm enables a new class of harmful adversarial ML attacks with a low entry barrier, which cannot be formalized with existing adversarial ML threat models,” the team wrote. “Furthermore, such vulnerabilities must be proactively assessed.”
Adversarial machine learning and artificial intelligence have been concerns within the infosec community for some time. While the number of attacks in the wild is believed to be extremely small, many experts have cautioned that algorithmic models can be vulnerable to poisoned data and influenced by threat actors.
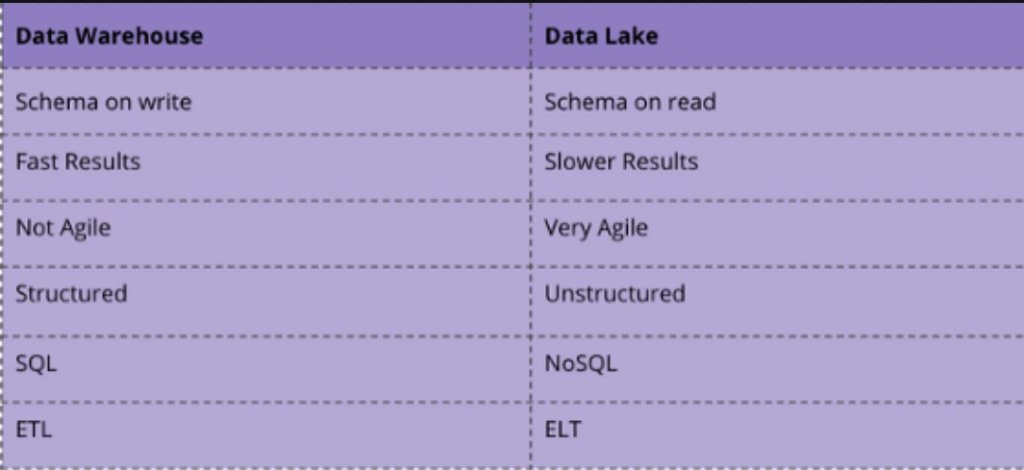
In addition to Data Warehouses, which are now firmly established in the corporate world, Data Lakes are also becoming increasingly common, and one often hears of Data Marts, but what is actually what?
The Data Warehouse
The Data Warehouse is an analytical, usually relational database (SQL) or hybrid system (Mix of SQL and NoSQL) created from different data sources. The goal is usually to store historical data for later analysis. Data Warehouses often have extensive computing and storage resources for running complicated queries and generating reports. They are often used as data sources for business intelligence and machine learning systems. New approaches, technologies and especially the cloud are changing the field a lot and offer new opportunities. Data Warehouses are classic relational systems that work with structured data. Exceptions are new cloud-based Data Warehouse technologies such as BigQuery or Snowflake which can also work with unstructured data and are column-based.
The Data Lake
The Data Lake, on the other hand, is a large pool of raw data for which no use has yet been determined. A Data Warehouse is a repository for structured, filtered data that has already been processed for a specific purpose [1].While Data Warehouses use the classic ETL process in combination with structured data in a relational database, a Data Lake uses paradigms such as ELT and a schema on-read as well as often unstructured data [2].
A Data Lake can also be used as the basis for a Data Warehouse, so that the data is then made available in structured form in the Data Warehouse from there.
The difference between Data Warehouse versus Data Lake .
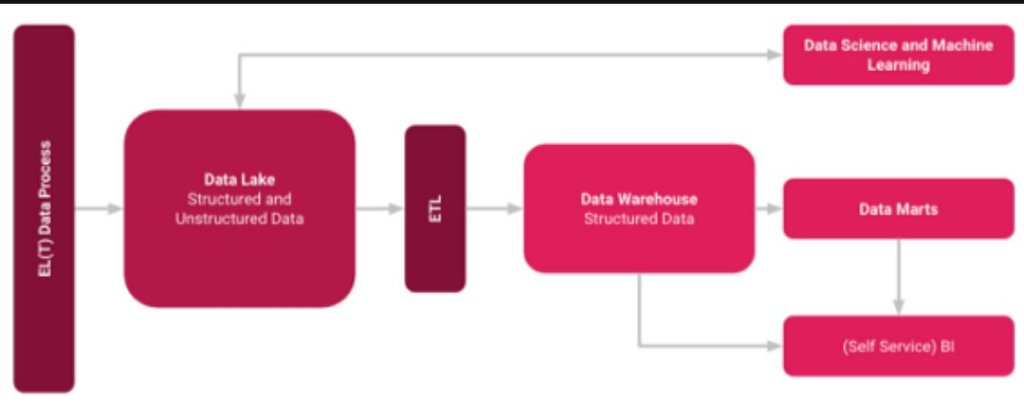
So what is a Data Lakehouse?
It is not just about integrating a Data Lake with a Data Warehouse, but rather integrating a Data Lake, a Data Warehouse, and purpose-built storage to enable unified governance and ease of data movement[3]. From my own experience it has often shown that Data Lakes can be realised much faster. Once all data is available, Data Warehouses can still be built on top of it as a hybrid solution.
Hybrid Data Lake-house concept
This makes rigid and classically planned Data Warehouses a thing of the past. This greatly accelerates the provision of dashboards and analyses and is a good step towards a data-driven culture. An implementation with new SaaS services from the cloud and approaches such as ELT instead of ETL also accelerates the development.
In my opinion, this approach has been around for some time, especially in the area of Cloud Data Warehousing and Data Lakes. Here, these two technologies have long been combined with each other in a hybrid approach (Read here more about it). In my opinion, the new trend term Data Lakehouse simply describes this established approach.
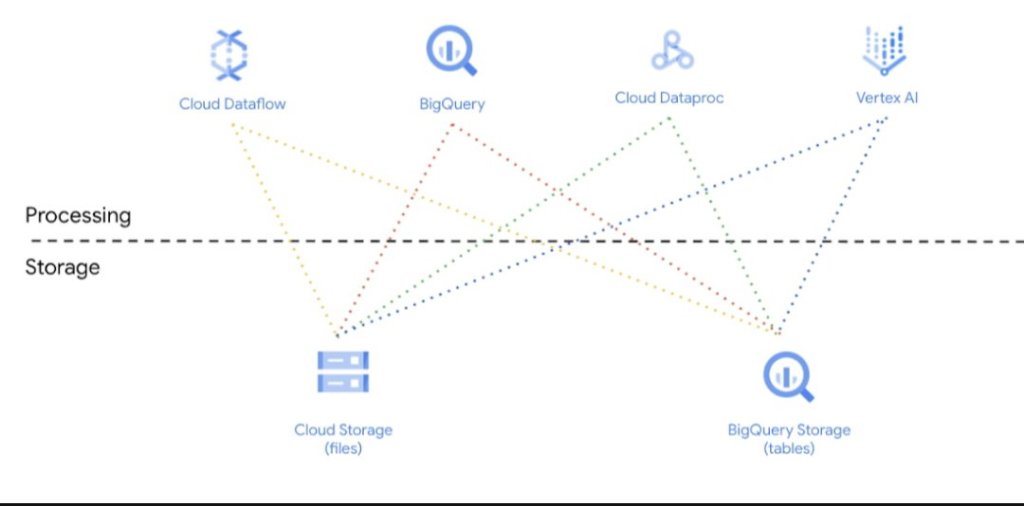
How to build up a Data Lakehouse?
To be a bit more concrete, we can take a look at how and with which technologies and services such Data Lakehouses can be built. In the figure below, an architecture is shown that was realised in the Google Cloud. Here, Cloud Storage and BigQuery are used as storage. Due to the good connectivity in Google Cloud, the services can easily exchange data with each other and thus be used for analysis, machine learning and other topics.
Data Lakehouse on GCP -Source Google
The Data Mart
The Data Mart contains data focused on a specific line of business. Normally they dependent on the Data Warehouse, but also could be indpenedent that is often when it’s originating from an operational database or system. They are therefore a subset of a Data Warehouse or a system. Data marts offer the advantage of faster data retrieval. Since they usually contain only a subset of the Data Warehouse, the amount of data in a data mart is consequently considerably smaller. This smaller amount of data provides a much faster result when queries are made [3].
Summary
Data Lakehouses combine the Data Lake with a Data Warehouse to enable unified governance and ease of data movement [4]. From the Data Warehouse, the data can then be distributed to BI layers, ML services or even Data Marts. Read here more about Data Lakehouses.
Artificial intelligence has made our life more dependent on computer software and machines, than ever before. In today’s Time’s , starting from our own virtual identity to transformations in our interpersonal lives , Artificial intelligence has influenced and harnessed the most important prospect of transforming the humans and their coexistence with other life forms into the planet.
Introduction
Our Planet has become a part of the next phase of development in human history , the data collection and data semantics have transformed to such an extent that today almost every application present on the internet has over 1million TB data pumping every million seconds. Imagine the power of learning and collecting knowledge.
It’s not that humans have just recently understood the power of knowledge , humans have collected & harnessed the power of knowledge, making it the sole reason for our species to have evolved and become the most dominant species on this planet.The power of collecting and understanding the on- going knowledge flowing through our community.
Assuming we are a very new subset of the homo erectus and if we look back to the existence of the planet called Pangea we would be able to understand why and how a two leg null developed and harnessed something like language or a mode of expressing and interacting with fellow homo erectus. There have been many incidences in the course of human history to prove that we have always thrived and co-existed and conquered on the basis of that acquired knowledge.
We have reached to the point that we want to create a clone of ourselves to help us understand ourselves better than us. We have reached a point where we are going to either evolve into meta humans or put ourselves on the line of extinction. Artificial intelligence or acquired knowledge has helped in problem solving on a daily basis, being said that let us understand the 10 most important roles artificial intelligence is going to play in the near future to transform into multi dimensional humans. At present artificial intelligence is the key behind every major advancement the human race is or has conjured in the recent past.
Ever since the start of the year 2020 Data science & learning, data analytics have become the most important subjects to human development, you would be amazing to know that almost 6 million TB of data is precisely collected and implemented to create or develop or evolve the human kind. In my eyes artificial intelligence is going to be the only reason for humans to evolve , grow & sustain the next 2000 years ,we as humans have always made sure that we advance ourselves into one particular aspect to change the course of our history ,starting from getting enlightened about fire to making wheels to making steam engines, satellite, rockets to making humanoids to replace ourselves with our permission for our existence.
So today I shall be giving my insights on the most important and crucial roles AI will play in sustaining , harnessing into meta humans. Already early artificial intelligence auditing co-exists with us To begin with I would be talking about the industrial , commercial & personal ways artificial intelligence helps us with.
Hi my name is Siddharth Rao , founder BetaDATA and I would be discussing the most crucial existential roles AI would play in evolving us to a multi-planetary species. By the end of this century we would start living on another planet making new sources of existence and nurturing and harbouring new sustainable environments for a different kind of US !
About AI
artificial intelligence (AI), the ability of a digital computer or computer-controlled robot to perform tasks commonly associated with intelligent beings. The term is frequently applied to the project of developing systems endowed with the intellectual processes characteristic of humans, such as the ability to reason, discover meaning, generalize, or learn from past experience. Since the development of the digital computer in the 1940s, it has been demonstrated that computers can be programmed to carry out very complex tasks—as, for example, discovering proofs for mathematical theorems or playing chess—with great proficiency.
Still, despite continuing advances in computer processing speed and memory capacity, there are as yet no programs that can match human flexibility over wider domains or in tasks requiring much everyday knowledge.
On the other hand, some programs have attained the performance levels of human experts and professionals in performing certain specific tasks, so that artificial intelligence in this limited sense is found in applications as diverse as medical diagnosis, computer search engines, and voice or handwriting recognition.
All but the simplest human behaviour is ascribed to intelligence, while even the most complicated insect behaviour is never taken as an indication of intelligence. What is the difference? Consider the behaviour of the digger wasp.Sphex ichneumoneus.
When the female wasp returns to her burrow with food, she first deposits it on the threshold, checks for intruders inside her burrow, and only then, if the coast is clear, carries her food inside. The real nature of the wasp’s instinctual behaviour is revealed if the food is moved a few inches away from the entrance to her burrow while she is inside: on emerging, she will repeat the whole procedure as often as the food is displaced. Intelligence—conspicuously absent in the case of Sphex—must include the ability to adapt to new circumstances.
Britannica tech quiz
Psychologists generally do not characterize human intelligence by just one trait but by the combination of many diverse abilities. Research in AI has focused chiefly on the following components of intelligence: learning, reasoning, problem solving,perception, and using language.
Learning : There are a number of different forms of learning as applied to artificial intelligence. The simplest is learning by trial and error. For example, a simple computer program for solving mate-in-one chess problems might try moves at random until mate is found. The program might then store the solution with the position so that the next time the computer encounters the same position it would recall the solution. This simple memorization of individual items and procedures—known as rote learning—is relatively easy to implement on a computer. More challenging is the problem of implementing what is called generalization. Generalization involves applying past experience to analogous new situations. For example, a program that learns the past tense of regular English verbs by rote will not be able to produce the past tense of a word such as jump unless it previously had been presented with jumped, whereas a program that is able to generalize can learn the “add ed” rule and so form the past tense of jump based on experience with similar verbs.
Reasoning The reason is to draw inferences appropriate to the situation. Inferences are classified as either deductive or inductive. An example of the former is, “Fred must be in either the museum or the café. He is not in the café; therefore he is in the museum,” and of the latter, “Previous accidents of this sort were caused by instrument failure; therefore this accident was caused by instrument failure.” The most significant difference between these forms of reasoning is that in the deductive case the truth of the premises guarantees the truth of the conclusion, whereas in the inductive case the truth of the premise lends support to the conclusion without giving absolute assurance. Inductive reasoning is common in science, where data is collected and tentative models are developed to describe and predict future behaviour—until the appearance of anomalous data forces the model to be revised. Deductive reasoning is common in mathematics and logic, where elaborate structures of irrefutable theorems are built up from a small set of basic axioms and rules.
There has been considerable success in programming computers to draw inferences, especially deductive inferences. However, true reasoning involves more than just drawing inferences; it involves drawing inferences relevant to the solution of the particular task or situation. This is one of the hardest problems confronting AI.
Problem solving Problem solving, particularly in artificial intelligence, may be characterized as a systematic search through a range of possible actions in order to reach some predefined goal or solution. Problem-solving methods divide into special purpose and general purpose. A special-purpose method is tailor-made for a particular problem and often exploits very specific features of the situation in which the problem is embedded. In contrast, a general-purpose method is applicable to a wide variety of problems. One general-purpose technique used in AI is means-end analysis—a step-by-step, or incremental, reduction of the difference between the current state and the final goal. The program selects actions from a list of means—in the case of a simple robot this might consist of PICKUP, PUTDOWN, MOVEFORWARD, MOVEBACK, MOVELEFT, and MOVERIGHT—until the goal is reached. Many diverse problems have been solved by artificial intelligence programs. Some examples are finding the winning move (or sequence of moves) in a board game, devising mathematical proofs, and manipulating “virtual objects” in a computer-generated world.
Perception In perception the environment is scanned by means of various sensory organs, real or artificial, and the scene is decomposed into separate objects in various spatial relationships. Analysis is complicated by the fact that an object may appear different depending on the angle from which it is viewed, the direction and intensity of illumination in the scene, and how much the object contrasts with the surrounding field.
At present, artificial perception is sufficiently well advanced to enable optical sensors to identify individuals, autonomous vehicles to drive at moderate speeds on the open road, and robots to roam through buildings collecting empty soda cans. One of the earliest systems to integrate perception and action was FREDDY, a stationary robot with a moving television eye and a pincer hand, constructed at the University of Edinburgh, Scotland, during the period 1966–73 under the direction of Donald Michie. FREDDY was able to recognize a variety of objects and could be instructed to assemble simple artifacts, such as a toy car, from a random heap of components.
Language A language is a system of signs having meaning by convention. In this sense, language need not be confined to the spoken word. Traffic signs, for example, form a mini language, it being a matter of convention that ⚠ means “hazard ahead” in some countries. It is distinctive of languages that linguistic units possess meaning by convention, and linguistic meaning is very different from what is called natural meaning, exemplified in statements such as “Those clouds mean rain” and “The fall in pressure means the valve is malfunctioning.”
An important characteristic of full-fledged human languages—in contrast to birdcalls and traffic signs—is their productivity. A productive language can formulate an unlimited variety of sentences.
It is relatively easy to write computer programs that seem able, in severely restricted contexts, to respond fluently in a human language to questions and statements. Although none of these programs actually understands language, they may, in principle, reach the point where their command of a language is indistinguishable from that of a normal human. What, then, is involved in genuine understanding, if even a computer that uses language like a native human speaker is not acknowledged to understand? There is no universally agreed upon answer to this difficult question. According to one theory, whether or not one understands depends not only on one’s behaviour but also on one’s history: in order to be said to understand, one must have learned the language and have been trained to take one’s place in the linguistic community by means of interaction with other language users.
Methods and goals in AI
Symbolic vs. connectionist approaches AI research follows two distinct, and to some extent competing, methods, the symbolic (or “top-down”) approach, and the connectionist (or “bottom-up”) approach. The top-down approach seeks to replicate intelligence by analysing cognition independent of the biological structure of the brain, in terms of the processing of symbols—whence the symbolic label. The bottom-up approach, on the other hand, involves creating artificial neural networks in imitation of the brain’s structure—whence the connectionist label.
To illustrate the difference between these approaches, consider the task of building a system, equipped with an optical scanner, that recognises the letters of the alphabet. A bottom-up approach typically involves training an artificial neural network by presenting letters to it one by one, gradually improving performance by “tuning” the network. (Tuning adjusts the responsiveness of different neural pathways to different stimuli.) In contrast, a top-down approach typically involves writing a computer program that compares each letter with geometric descriptions. Simply put, neural activities are the basis of the bottom-up approach, while symbolic descriptions are the basis of the top-down approach.
computer chip. computer. Hand holding computer chip. Central processing unit (CPU). history and society, science and technology, microchip, microprocessor motherboard computer Circuit Board
The evolution of AI
The fundamentals of learning.
In The Fundamentals of Learning (1932), Edward Thorndike, a psychologist at Columbia University, New York City, first suggested that human learning consists of some unknown property of connections between neurons in the brain. In The Organization of Behavior (1949), Donald Hebb, a psychologist at McGill University, Montreal, Canada, suggested that learning specifically involves strengthening certain patterns of neural activity by increasing the probability (weight) of induced neuron firing between the associated connections. The notion of weighted connections is described in a later section, Connectionism.
In 1957 two vigorous advocates of symbolic AI—Allen Newell, a researcher at the RAND Corporation, Santa Monica, California, and Herbert Simon, a psychologist and computer scientist at Carnegie Mellon University, Pittsburgh, Pennsylvania—summed up the top-down approach in what they called the physical symbol system hypothesis. This hypothesis states that processing structures of symbols is sufficient, in principle, to produce artificial intelligence in a digital computer and that, moreover, human intelligence is the result of the same type of symbolic manipulations.
During the 1950s and ’60s the top-down and bottom-up approaches were pursued simultaneously, and both achieved noteworthy, if limited, results. During the 1970s, however, bottom-up AI was neglected, and it was not until the 1980s that this approach again became prominent. Nowadays both approaches are followed, and both are acknowledged as facing difficulties. Symbolic techniques work in simplified realms but typically break down when confronted with the real world; meanwhile, bottom-up researchers have been unable to replicate the nervous systems of even the simplest living things. Caenorhabditis elegans, a much-studied worm, has approximately 300 neurons whose pattern of interconnections is perfectly known. Yet connectionist models have failed to mimic even this worm. Evidently, the neurons of connectionist theory are gross oversimplifications of the real thing.
Strong AI, applied AI, and cognitive simulation
Employing the methods outlined above, AI research attempts to reach one of three goals: strong AI, applied AI, or cognitive simulation. Strong AI aims to build machines that think. (The term strong AI was introduced for this category of research in 1980 by the philosopher John Searle of the University of California at Berkeley.) The ultimate ambition of strong AI is to produce a machine whose overall intellectual ability is indistinguishable from that of a human being. As is described in the section Early milestones in AI, this goal generated great interest in the 1950s and ’60s, but such optimism has given way to an appreciation of the extreme difficulties involved. To date, progress has been meagre. Some critics doubt whether research will produce even a system with the overall intellectual ability of an ant in the foreseeable future. Indeed, some researchers working in AI’s other two branches view strong AI as not worth pursuing.
Applied AI, also known as advanced information processing, aims to produce commercially viable “smart” systems—for example, “expert” medical diagnosis systems and stock-trading systems. Applied AI has enjoyed considerable success, as described in the section Expert systems.
In cognitive simulation, computers are used to test theories about how the human mind works—for example, theories about how people recognize faces or recall memories. Cognitive simulation is already a powerful tool in both neuroscience and cognitive psychology.
Theoretical work The earliest substantial work in the field of artificial intelligence was done in the mid-20th century by the British logician and computer pioneer Alan Mathison Turing. In 1935 Turing described an abstract computing machine consisting of a limitless memory and a scanner that moves back and forth through the memory, symbol by symbol, reading what it finds and writing further symbols.
The actions of the scanner are dictated by a program of instructions that also is stored in the memory in the form of symbols. This is Turing’s stored-program concept, and implicit in it is the possibility of the machine operating on, and so modifying or improving, its own program. Turing’s conception is now known simply as the universal Turing machine. All modern computers are in essence universal Turing machines.
During World War II, Turing was a leading cryptanalyst at the Government Code and Cypher School in Bletchley Park, Buckinghamshire, England. Turing could not turn to the project of building a stored-program electronic computing machine until the cessation of hostilities in Europe in 1945. Nevertheless, during the war he gave considerable thought to the issue of machine intelligence. One of Turing’s colleagues at Bletchley Park, Donald Michie (who later founded the Department of Machine Intelligence and Perception at the University of Edinburgh), later recalled that Turing often discussed how computers could learn from experience as well as solve new problems through the use of guiding principles—a process now known as heuristic problem solving.
Figure 1.
Turing gave quite possibly the earliest public lecture (London, 1947) to mention computer intelligence, saying, “What we want is a machine that can learn from experience,” and that the “possibility of letting the machine alter its own instructions provides the mechanism for this.” In 1948 he introduced many of the central concepts of AI in a report entitled “Intelligent Machinery.” However, Turing did not publish this paper, and many of his ideas were later reinvented by others. For instance, one of Turing’s original ideas was to train a network of artificial neurons to perform specific tasks, an approach described in the section Connectionism.
Chess
At Bletchley Park, Turing illustrated his ideas on machine intelligence by reference to chess—a useful source of challenging and clearly defined problems against which proposed methods for problem solving could be tested. In principle, a chess-playing computer could play by searching exhaustively through all the available moves, but in practice this is impossible because it would involve examining an astronomically large number of moves. Heuristics are necessary to guide a narrower, more discriminative search. Although Turing experimented with designing chess programs, he had to content himself with theory in the absence of a computer to run his chess program. The first true AI programs had to await the arrival of stored-program electronic digital computers.
In 1945 Turing predicted that computers would one day play very good chess, and just over 50 years later, in 1997, Deep Blue, a chess computer built by the International Business Machines Corporation (IBM), beat the reigning world champion, Garry Kasparov, in a six-game match. While Turing’s prediction came true, his expectation that chess programming would contribute to the understanding of how human beings think did not. The huge improvement in computer chess since Turing’s day is attributable to advances in computer engineering rather than advances in AI—Deep Blue’s 256 parallel processors enabled it to examine 200 million possible moves per second and to look ahead as many as 14 turns of play. Many agree with Noam Chomsky, a linguist at the Massachusetts Institute of Technology (MIT), who opined that a computer beating a grandmaster at chess is about as interesting as a bulldozer winning an Olympic weightlifting competition.
In 1950 Turing sidestepped the traditional debate concerning the definition of intelligence, introducing a practical test for computer intelligence that is now known simply as the Turing test. The Turing test involves three participants: a computer, a human interrogator, and a human foil. The interrogator attempts to determine, by asking questions of the other two participants, which is the computer. All communication is via keyboard and display screen. The interrogator may ask questions as penetrating and wide-ranging as he or she likes, and the computer is permitted to do everything possible to force a wrong identification. (For instance, the computer might answer, “No,” in response to, “Are you a computer?” and might follow a request to multiply one large number by another with a long pause and an incorrect answer.) The foil must help the interrogator to make a correct identification. A number of different people play the roles of interrogator and foil, and, if a sufficient proportion of the interrogators are unable to distinguish the computer from the human being, then (according to proponents of Turing’s test) the computer is considered an intelligent, thinking entity.
In 1991 the American philanthropist Hugh Loebner started the annual Loebner Prize competition, promising a $100,000 payout to the first computer to pass the Turing test and awarding $2,000 each year to the best effort. However, no AI program has come close to passing an undiluted Turing test.
Early milestones in AI
The first AI programs
The earliest successful AI program was written in 1951 by Christopher Strachey, later director of the Programming Research Group at the University of Oxford. Strachey’s checkers (draughts) program ran on the Ferranti Mark I computer at the University of Manchester, England. By the summer of 1952 this program could play a complete game of checkers at a reasonable speed.
Information about the earliest successful demonstration of machine learning was published in 1952. A shopper, written by Anthony Oettinger at the University of Cambridge, ran on the EDSAC computer. Shopper’s simulated world was a mall of eight shops. When instructed to purchase an item, Shopper would search for it, visiting shops at random until the item was found. While searching, Shopper would memorize a few of the items stocked in each shop visited (just as a human shopper might). The next time Shopper was sent out for the same item, or for some other item that it had already located, it would go to the right shop straight away. This simple form of learning, as is pointed out in the introductory section What is intelligence?, is called rote learning.
The first AI program to run in the United States also was a checkers program, written in 1952 by Arthur Samuel for the prototype of the IBM 701. Samuel took over the essentials of Strachey’s checkers program and over a period of years considerably extended it. In 1955 he added features that enabled the program to learn from experience. Samuel included mechanisms for both rote learning and generalization, enhancements that eventually led to his program’s winning one game against a former Connecticut checkers champion in 1962.
Artificial Intelligence (AI) is the mantra of the current era. The phrase is intoned by technologists, academicians, journalists and venture capitalists alike. As with many phrases that cross over from technical academic fields into general circulation, there is significant misunderstanding accompanying the use of the phrase. But this is not the classical case of the public not understanding the scientists — here the scientists are often as befuddled as the public. The idea that our era is somehow seeing the emergence of an intelligence in silicon that rivals our own entertains all of us — enthralling us and frightening us in equal measure. And, unfortunately, it distracts us.
There is a different narrative that one can tell about the current era. Consider the following story, which involves humans, computers, data and life-or-death decisions, but where the focus is something other than intelligence-in-silicon fantasies. When my spouse was pregnant 14 years ago, we had an ultrasound. There was a geneticist in the room, and she pointed out some white spots around the heart of the fetus. “Those are markers for Down syndrome,” she noted, “and your risk has now gone up to 1 in 20.” She further let us know that we could learn whether the fetus in fact had the genetic modification underlying Down syndrome via an amniocentesis. But amniocentesis was risky — the risk of killing the fetus during the procedure was roughly 1 in 300. Being a statistician, I determined to find out where these numbers were coming from. To cut a long story short, I discovered that a statistical analysis had been done a decade previously in the UK, where these white spots, which reflect calcium buildup, were indeed established as a predictor of Down syndrome. But I also noticed that the imaging machine used in our test had a few hundred more pixels per square inch than the machine used in the UK study. I went back to tell the geneticist that I believed that the white spots were likely false positives — that they were literally “white noise.” She said “Ah, that explains why we started seeing an uptick in Down syndrome diagnoses a few years ago; it’s when the new machine arrived.”
Machine learning and smart ways of learning
We didn’t do the amniocentesis, and a healthy girl was born a few months later. But the episode troubled me, particularly after a back-of-the-envelope calculation convinced me that many thousands of people had gotten that diagnosis that same day worldwide, that many of them had opted for amniocentesis, and that a number of babies had died needlessly. And this happened day after day until it somehow got fixed. The problem that this episode revealed wasn’t about my individual medical care; it was about a medical system that measured variables and outcomes in various places and times, conducted statistical analyses, and made use of the results in other places and times. The problem had to do not just with data analysis per se, but with what database researchers call “provenance” — broadly, where did data arise, what inferences were drawn from the data, and how relevant are those inferences to the present situation? While a trained human might be able to work all of this out on a case-by-case basis, the issue was that of designing a planetary-scale medical system that could do this without the need for such detailed human oversight
I’m also a computer scientist, and it occurred to me that the principles needed to build planetary-scale inference-and-decision-making systems of this kind, blending computer science with statistics, and taking into account human utilities, were nowhere to be found in my education. And it occurred to me that the development of such principles — which will be needed not only in the medical domain but also in domains such as commerce, transportation and education — were at least as important as those of building AI systems that can dazzle us with their game-playing or sensorimotor skills.
Whether or not we come to understand “intelligence” any time soon, we do have a major challenge on our hands in bringing together computers and humans in ways that enhance human life. While this challenge is viewed by some as subservient to the creation of “artificial intelligence,” it can also be viewed more prosaically — but with no less reverence — as the creation of a new branch of engineering. Much like civil engineering and chemical engineering in decades past, this new discipline aims to corral the power of a few key ideas, bringing new resources and capabilities to people, and doing so safely. Whereas civil engineering and chemical engineering were built on physics and chemistry, this new engineering discipline will be built on ideas that the preceding century gave substance to — ideas such as “information,” “algorithm,” “data,” “uncertainty,” “computing,” “inference,” and “optimization.” Moreover, since much of the focus of the new discipline will be on data from and about humans, its development will require perspectives from the social sciences and humanities.
While the building blocks have begun to emerge, the principles for putting these blocks together have not yet emerged, and so the blocks are currently being put together in ad-hoc ways.
Thus, just as humans built buildings and bridges before there was civil engineering, humans are proceeding with the building of societal-scale, inference-and-decision-making systems that involve machines, humans and the environment. Just as early buildings and bridges sometimes fell to the ground — in unforeseen ways and with tragic consequences — many of our early societal-scale inference-and-decision-making systems are already exposing serious conceptual flaws.
And, unfortunately, we are not very good at anticipating what the next emerging serious flaw will be. What we’re missing is an engineering discipline with its principles of analysis and design.
The current public dialog about these issues too often uses “AI” as an intellectual wildcard, one that makes it difficult to reason about the scope and consequences of emerging technology. Let us begin by considering more carefully what “AI” has been used to refer to, both recently and historically.
Most of what is being called “AI” today, particularly in the public sphere, is what has been called “Machine Learning” (ML) for the past several decades. ML is an algorithmic field that blends ideas from statistics, computer science and many other disciplines (see below) to design algorithms that process data, make predictions and help make decisions. In terms of impact on the real world, ML is the real thing, and not just recently. Indeed, that ML would grow into massive industrial relevance was already clear in the early 1990s, and by the turn of the century forward-looking companies such as Amazon were already using ML throughout their business, solving mission-critical back-end problems in fraud detection and supply-chain prediction, and building innovative consumer-facing services such as recommendation systems. As datasets and computing resources grew rapidly over the ensuing two decades, it became clear that ML would soon power not only Amazon but essentially any company in which decisions could be tied to large-scale data. New business models would emerge. The phrase “Data Science” began to be used to refer to this phenomenon, reflecting the need of ML algorithms experts to partner with database and distributed-systems experts to build scalable, robust ML systems, and reflecting the larger social and environmental scope of the resulting systems.
This confluence of ideas and technology trends has been rebranded as “AI” over the past few years. This rebranding is worthy of some scrutiny.
Historically, the phrase “AI” was coined in the late 1950’s to refer to the heady aspiration of realizing in software and hardware an entity possessing human-level intelligence. We will use the phrase “human-imitative AI” to refer to this aspiration, emphasizing the notion that the artificially intelligent entity should seem to be one of us, if not physically at least mentally (whatever that might mean). This was largely an academic enterprise. While related academic fields such as operations research, statistics, pattern recognition, information theory and control theory already existed, and were often inspired by human intelligence (and animal intelligence), these fields were arguably focused on “low-level” signals and decisions. The ability of, say, a squirrel to perceive the three-dimensional structure of the forest it lives in, and to leap among its branches, was inspirational to these fields. “AI” was meant to focus on something different — the “high-level” or “cognitive” capability of humans to “reason” and to “think.” Sixty years later, however, high-level reasoning and thought remain elusive. The developments which are now being called “AI” arose mostly in the engineering fields associated with low-level pattern recognition and movement control, and in the field of statistics — the discipline focused on finding patterns in data and on making well-founded predictions, tests of hypotheses and decisions.
Indeed, the famous “backpropagation” algorithm that was rediscovered by David Rumelhart in the early 1980s, and which is now viewed as being at the core of the so-called “AI revolution,” first arose in the field of control theory in the 1950s and 1960s. One of its early applications was to optimize the thrusts of the Apollo spaceships as they headed towards the moon.
Since the 1960s much progress has been made, but it has arguably not come about from the pursuit of human-imitative AI. Rather, as in the case of the Apollo spaceships, these ideas have often been hidden behind the scenes, and have been the handiwork of researchers focused on specific engineering challenges. Although not visible to the general public, research and systems-building in areas such as document retrieval, text classification, fraud detection, recommendation systems, personalized search, social network analysis, planning, diagnostics and A/B testing have been a major success — these are the advances that have powered companies such as Google, Netflix, Facebook and Amazon.
One could simply agree to refer to all of this as “AI,” and indeed that is what appears to have happened. Such labeling may come as a surprise to optimization or statistics researchers, who wake up to find themselves suddenly referred to as “AI researchers.” But labeling of researchers aside, the bigger problem is that the use of this single, ill-defined acronym prevents a clear understanding of the range of intellectual and commercial issues at play.
The past two decades have seen major progress — in industry and academia — in a complementary aspiration to human-imitative AI that is often referred to as “Intelligence Augmentation” (IA). Here computation and data are used to create services that augment human intelligence and creativity. A search engine can be viewed as an example of IA (it augments human memory and factual knowledge), as can natural language translation (it augments the ability of a human to communicate). Computing-based generation of sounds and images serves as a palette and creativity enhancer for artists. While services of this kind could conceivably involve high-level reasoning and thought, currently they don’t — they mostly perform various kinds of string-matching and numerical operations that capture patterns that humans can make use of.
Hoping that the reader will tolerate one last acronym, let us conceive broadly of a discipline of “Intelligent Infrastructure” (II), whereby a web of computation, data and physical entities exists that makes human environments more supportive, interesting and safe. Such infrastructure is beginning to make its appearance in domains such as transportation, medicine, commerce and finance, with vast implications for individual humans and societies. This emergence sometimes arises in conversations about an “Internet of Things,” but that effort generally refers to the mere problem of getting “things” onto the Internet — not to the far grander set of challenges associated with these “things” capable of analyzing those data streams to discover facts about the world, and interacting with humans and other “things” at a far higher level of abstraction than mere bits.
For example, returning to my personal anecdote, we might imagine living our lives in a “societal-scale medical system” that sets up data flows, and data-analysis flows, between doctors and devices positioned in and around human bodies, thereby able to aid human intelligence in making diagnoses and providing care. The system would incorporate information from cells in the body, DNA, blood tests, environment, population genetics and the vast scientific literature on drugs and treatments. It would not just focus on a single patient and a doctor, but on relationships among all humans — just as current medical testing allows experiments done on one set of humans (or animals) to be brought to bear in the care of other humans. It would help maintain notions of relevance, provenance and reliability, in the way that the current banking system focuses on such challenges in the domain of finance and payment. And, while one can foresee many problems arising in such a system — involving privacy issues, liability issues, security issues, etc — these problems should properly be viewed as challenges, not show-stoppers.
We now come to a critical issue: Is working on classical human-imitative AI the best or only way to focus on these larger challenges? Some of the most heralded recent success stories of ML have in fact been in areas associated with human-imitative AI — areas such as computer vision, speech recognition, game-playing and robotics. So perhaps we should simply await further progress in domains such as these. There are two points to make here. First, although one would not know it from reading the newspapers, success in human-imitative AI has in fact been limited — we are very far from realizing human-imitative AI aspirations. Unfortunately the thrill (and fear) of making even limited progress on human-imitative AI gives rise to levels of over-exuberance and media attention that is not present in other areas of engineering.
Second, and more importantly, success in these domains is neither sufficient nor necessary to solve important IA and II problems. On the sufficiency side, consider self-driving cars. For such technology to be realized, a range of engineering problems will need to be solved that may have little relationship to human competencies (or human lack-of-competencies). The overall transportation system (an II system) will likely more closely resemble the current air-traffic control system than the current collection of loosely-coupled, forward-facing, inattentive human drivers. It will be vastly more complex than the current air-traffic control system, specifically in its use of massive amounts of data and adaptive statistical modeling to inform fine-grained decisions. It is those challenges that need to be in the forefront, and in such an effort a focus on human-imitative AI may be a distraction.
As for the necessity argument, it is sometimes argued that the human-imitative AI aspiration subsumes IA and II aspirations, because a human-imitative AI system would not only be able to solve the classical problems of AI (as embodied, e.g., in the Turing test), but it would also be our best bet for solving IA and II problems. Such an argument has little historical precedent. Did civil engineering develop by envisaging the creation of an artificial carpenter or bricklayer? Should chemical engineering have been framed in terms of creating an artificial chemist? Even more polemically: if our goal was to build chemical factories, should we have first created an artificial chemist who would have then worked out how to build a chemical factory?
We need to realize that the current public dialog on AI — which focuses on a narrow subset of industry and a narrow subset of academia — risks blinding us to the challenges and opportunities that are presented by the full scope of AI, IA and II.
BetaDATA
A related argument is that human intelligence is the only kind of intelligence that we know, and that we should aim to mimic it as a first step. But humans are in fact not very good at some kinds of reasoning — we have our lapses, biases and limitations. Moreover, critically, we did not evolve to perform the kinds of large-scale decision-making that modern II systems must face, nor to cope with the kinds of uncertainty that arise in II contexts. One could argue that an AI system would not only imitate human intelligence, but also “correct” it, and would also scale to arbitrarily large problems. But we are now in the realm of science fiction — such speculative arguments, while entertaining in the setting of fiction, should not be our principal strategy going forward in the face of the critical IA and II problems that are beginning to emerge. We need to solve IA and II problems on their own merits, not as a mere corollary to a human-imitative AI agenda.
It is not hard to pinpoint algorithmic and infrastructure challenges in II systems that are not central themes in human-imitative AI research. II systems require the ability to manage distributed repositories of knowledge that are rapidly changing and are likely to be globally incoherent. Such systems must cope with cloud-edge interactions in making timely, distributed decisions and they must deal with long-tail phenomena whereby there is lots of data on some individuals and little data on most individuals. They must address the difficulties of sharing data across administrative and competitive boundaries. Finally, and of particular importance, II systems must bring economic ideas such as incentives and pricing into the realm of the statistical and computational infrastructures that link humans to each other and to valued goods. Such II systems can be viewed as not merely providing a service, but as creating markets. There are domains such as music, literature and journalism that are crying out for the emergence of such markets, where data analysis links producers and consumers. And this must all be done within the context of evolving societal, ethical and legal norms.
Of course, classical human-imitative AI problems remain of great interest as well. However, the current focus on doing AI research via the gathering of data, the deployment of “deep learning” infrastructure, and the demonstration of systems that mimic certain narrowly-defined human skills — with little in the way of emerging explanatory principles — tends to deflect attention from major open problems in classical AI. These problems include the need to bring meaning and reasoning into systems that perform natural language processing, the need to infer and represent causality, the need to develop computationally-tractable representations of uncertainty and the need to develop systems that formulate and pursue long-term goals. These are classical goals in human-imitative AI, but in the current hubbub over the “AI revolution,” it is easy to forget that they are not yet solved.
IA will also remain quite essential, because for the foreseeable future, computers will not be able to match humans in their ability to reason abstractly about real-world situations. We will need well-thought-out interactions of humans and computers to solve our most pressing problems. And we will want computers to trigger new levels of human creativity, not replace human creativity (whatever that might mean).
It was John McCarthy (while a professor at Dartmouth, and soon to take a position at MIT) who coined the term “AI,” apparently to distinguish his budding research agenda from that of Norbert Wiener (then an older professor at MIT). Wiener had coined “cybernetics” to refer to his own vision of intelligent systems — a vision that was closely tied to operations research, statistics, pattern recognition, information theory and control theory. McCarthy, on the other hand, emphasized the ties to logic. In an interesting reversal, it is Wiener’s intellectual agenda that has come to dominate in the current era, under the banner of McCarthy’s terminology. (This state of affairs is surely, however, only temporary; the pendulum swings more in AI than in most fields.)
But we need to move beyond the particular historical perspectives of McCarthy and Wiener.
This scope is less about the realization of science-fiction dreams or nightmares of super-human machines, and more about the need for humans to understand and shape technology as it becomes ever more present and influential in their daily lives. Moreover, in this understanding and shaping there is a need for a diverse set of voices from all walks of life, not merely a dialog among the technologically attuned. Focusing narrowly on human-imitative AI prevents an appropriately wide range of voices from being heard.
While industry will continue to drive many developments, academia will also continue to play an essential role, not only in providing some of the most innovative technical ideas, but also in bringing researchers from the computational and statistical disciplines together with researchers from other disciplines whose contributions and perspectives are sorely needed — notably the social sciences, the cognitive sciences and the humanities.
On the other hand, while the humanities and the sciences are essential as we go forward, we should also not pretend that we are talking about something other than an engineering effort of unprecedented scale and scope — society is aiming to build new kinds of artifacts. These artifacts should be built to work as claimed. We do not want to build systems that help us with medical treatments, transportation options and commercial opportunities to find out after the fact that these systems don’t really work — that they make errors that take their toll in terms of human lives and happiness. In this regard, as I have emphasized, there is an engineering discipline yet to emerge for the data-focused and learning-focused fields. As exciting as these latter fields appear to be, they cannot yet be viewed as constituting an engineering discipline.
we are witnessing is the creation of a new branch of engineering. The term “engineering” is often invoked in a narrow sense — in academia and beyond — with overtones of cold, affectless machinery, and negative connotations of loss of control by humans. But an engineering discipline can be what we want it to be.
In the current era, we have a real opportunity to conceive of something historically new — a human-centric engineering discipline.
I will resist giving this emerging discipline a name, but if the acronym “AI” continues to be used as placeholder nomenclature going forward, let’s be aware of the very real limitations of this placeholder. Let’s broaden our scope, tone down the hype and recognize the serious challenges ahead.
Acknowledgments: There are a number of individuals whose comments during the writing of this article have helped me greatly, including Jeff Bezos, Dave Blei, Rod Brooks, Cathryn Carson, Tom Dietterich, Charles Elkan, Oren Etzioni, David Heckerman, Douglas Hofstadter, Michael Kearns, Tammy Kolda, Ed Lazowska, John Markoff, Esther Rolf, Maja Mataric, Dimitris Papailiopoulos, Ben Recht, Theodoros Rekatsinas, Barbara Rosario and Ion Stoica. And I would like to add a special thanks to Cameron Baradar at The House, who first encouraged me to contemplate writing such a piece.